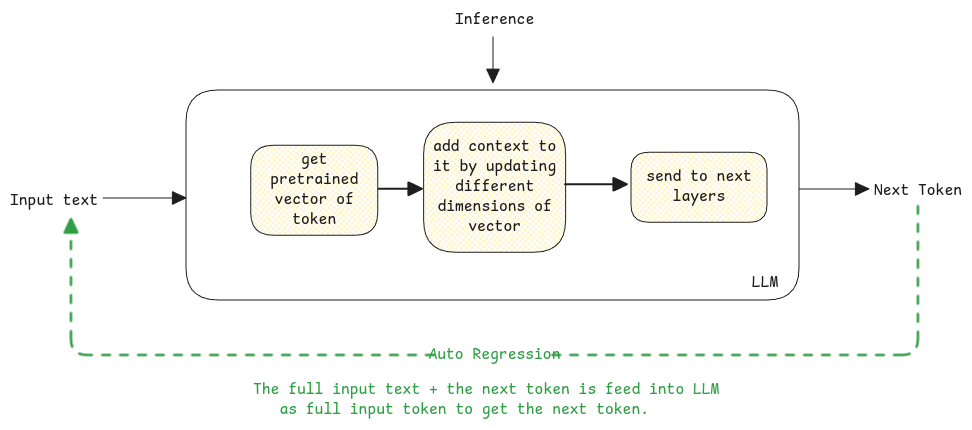
Next Token Prediction
An LLM's output is always about predicting the next best token, or next word.
Example - Which is the capital of France?
The output is the next best word after the full text. So: Which is the capital of France? {$answer token}.
The whole input plus the generated tokens, word by word, is passed back to the LLM. This repeats until the full output is done.
Probability
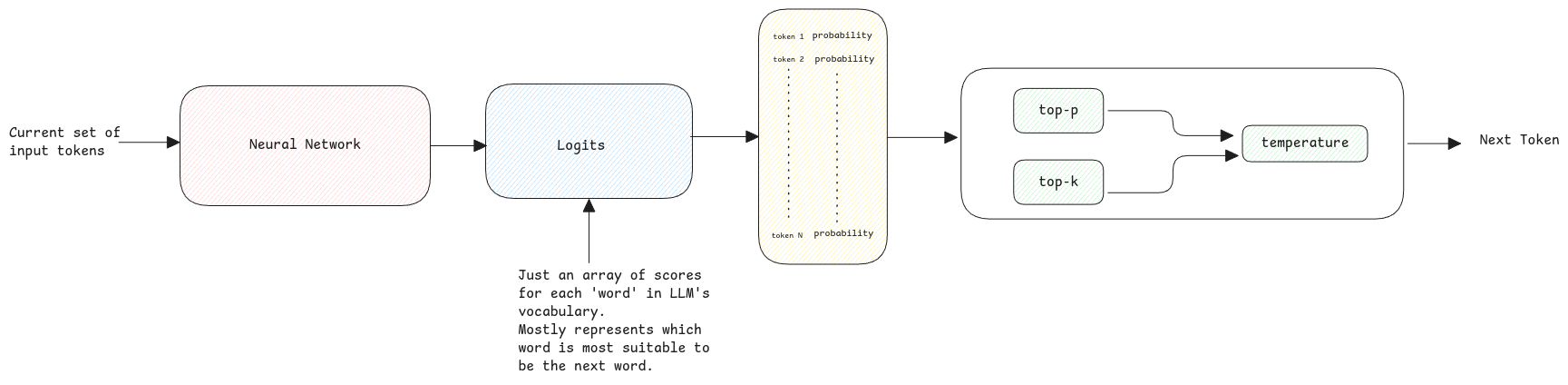
The neural network output is always an array of float values. It holds one for each token in the LLM's vocabulary.
This value is then converted into probabilities.
Sampling
Sampling is a statistics method. It uses a subset of items to predict the whole.
For an LLM, sampling is done from the next token's probability distribution. It takes only a subset of tokens, based on temperature, Top-P, and Top-K.
-
Temperature: This parameter shapes how the LLM picks a token. Higher temperature gives more random output. At the lowest (0.0), it always returns the highest-probability value.
-
Top-P: This parameter sets how many tokens to consider. The LLM keeps the top tokens whose probabilities add up to the Top-P value.
-
Top-K: It just keeps the top-K tokens with the highest probability.
Greedy Decoding
With greedy decoding, the model always picks the highest-probability token. For example, temperature 0.0, Top-P 0.0, and Top-K 1.0.
LLMs only know how two things relate. They don't know cause and effect.