Interpreter
Think of the JVM interpreter as a script reader for .class files. Bash reads a shell script line by line and runs it. In the same way, the JVM interpreter reads the byte code instructions one by one and runs them.
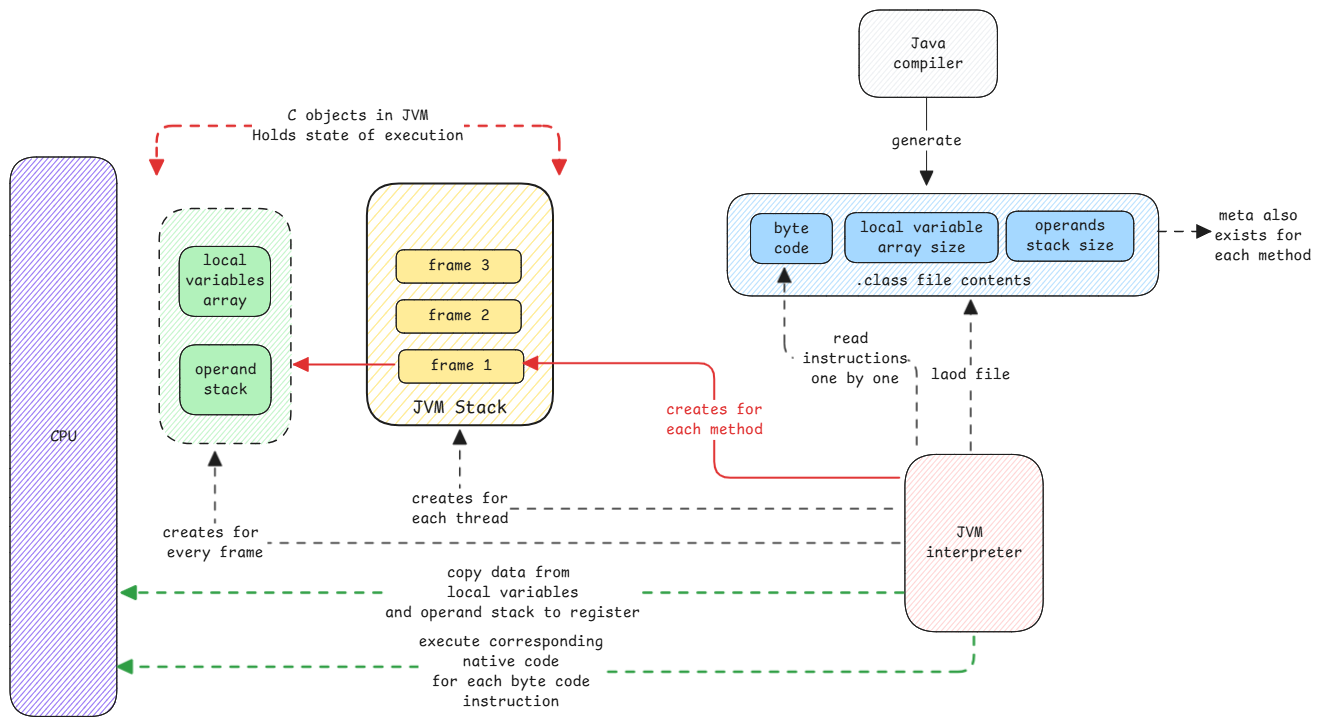
The JVM is basically an infinite loop. It keeps reading byte code instructions. A big switch case then runs each one based on its opcode.
When the code is compiled, it becomes an array of instructions. The interpreter reads this array one by one and runs it.
Interpreter isn't efficient
The interpreter always uses more memory. It works with a local variable array and an operand stack. It's also slower. It reads each instruction one by one and runs the matching native code.
Still, this keeps things simple and portable. With its own stack and local variable array, it need not worry about registers. Byte code is also smaller. It only deals with stack operations, not register ones.
With a stack, the byte code instructions are smaller. They need not name registers.
For example, iadd names no operands.
The operands are implied to be on top of the stack.
We never pass any to it.
Handover between application code and interpreter?
When the JVM starts, it finds the byte code of the main class and runs it.
No handover happens between the app code and the interpreter. The interpreter just reads the main class's byte code and runs it one by one.
When the interpreter runs, no app code runs. The interpreter is the code that runs. It runs the native instructions mapped to each app byte code instruction.